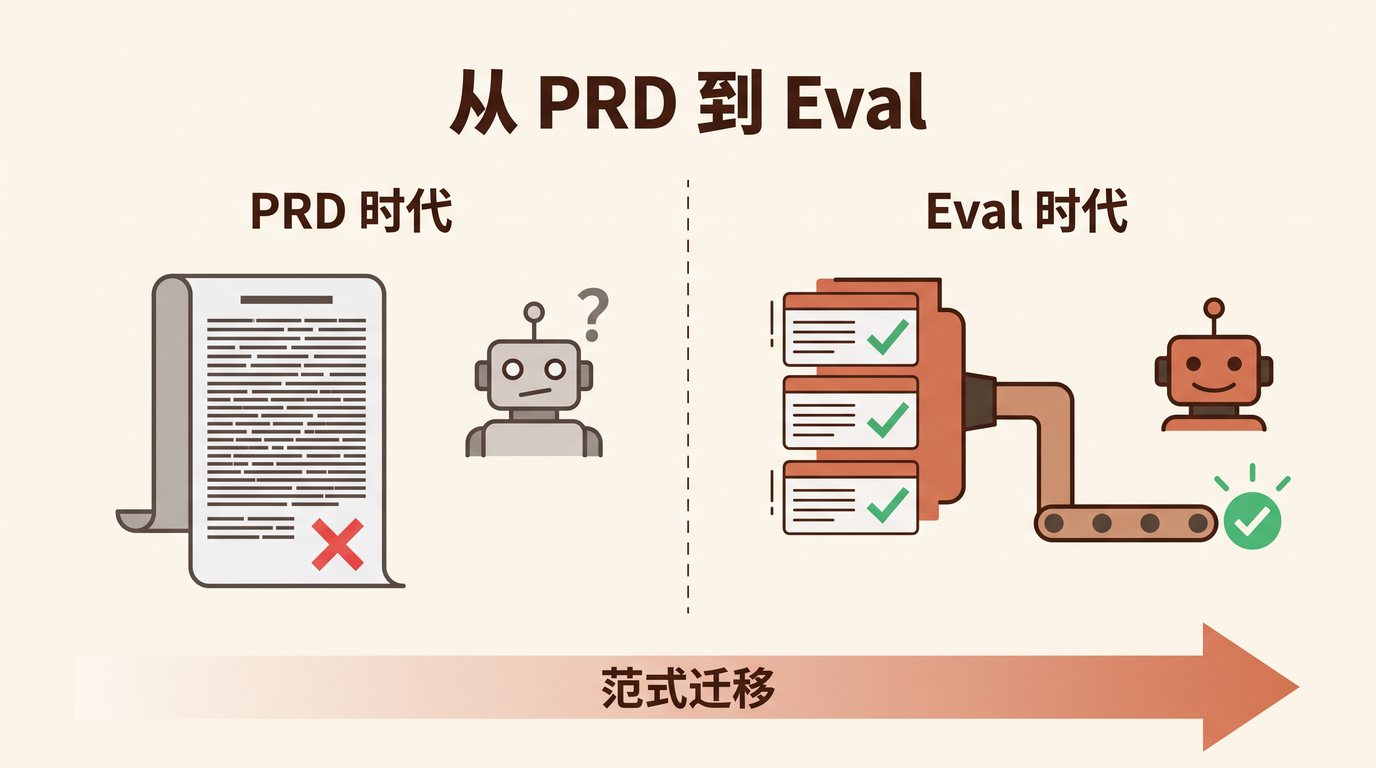
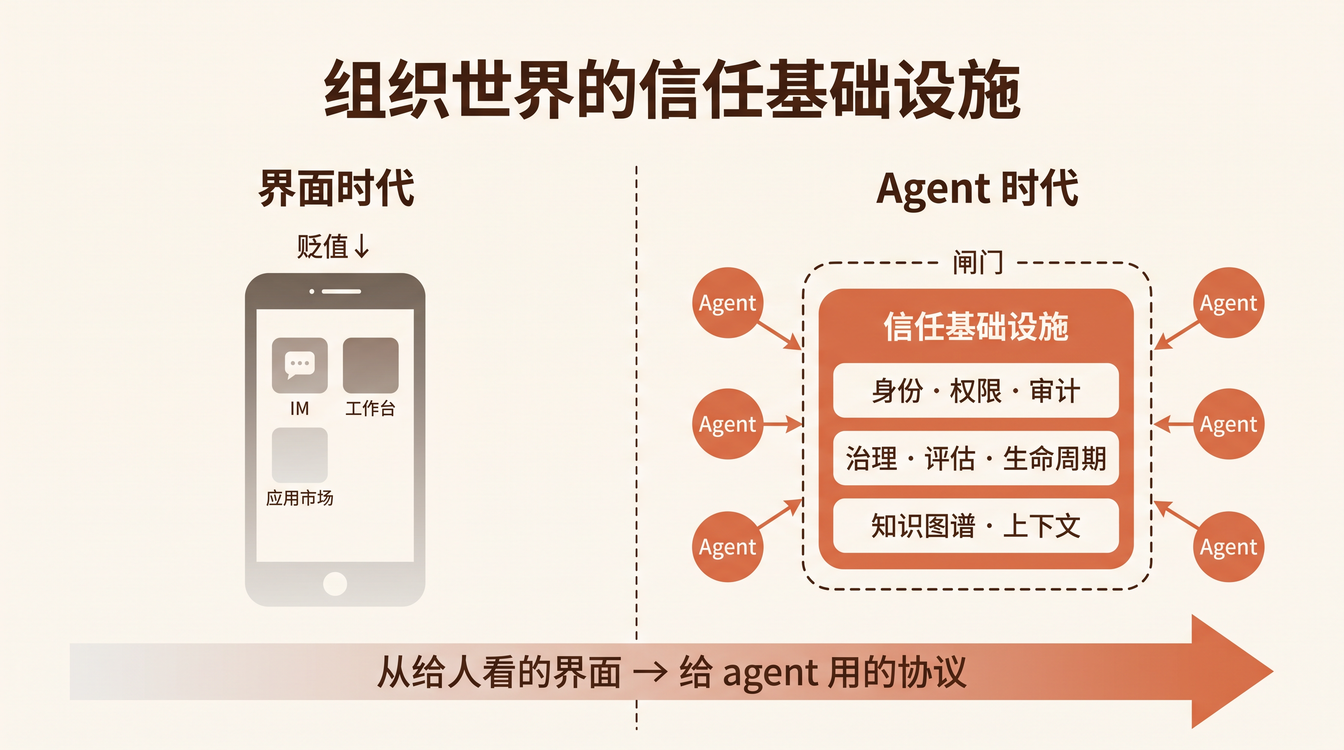
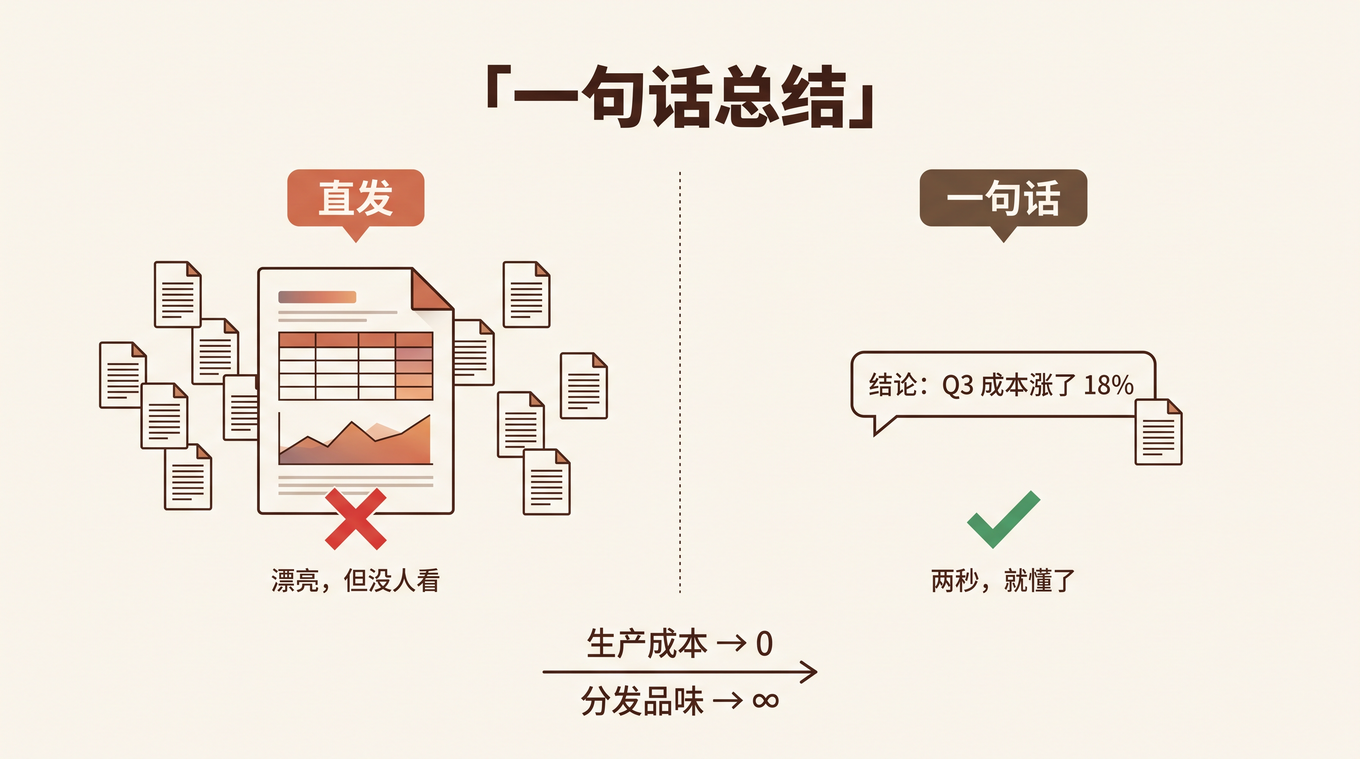
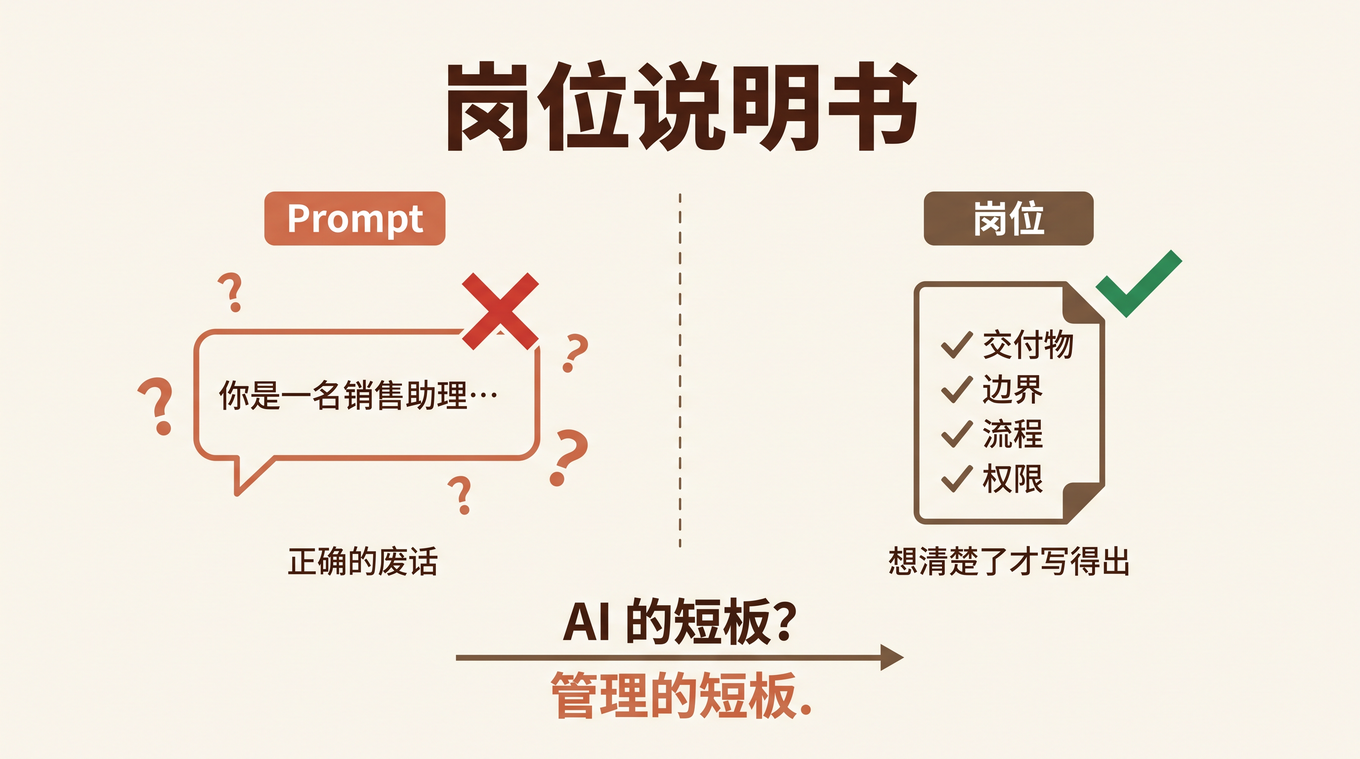
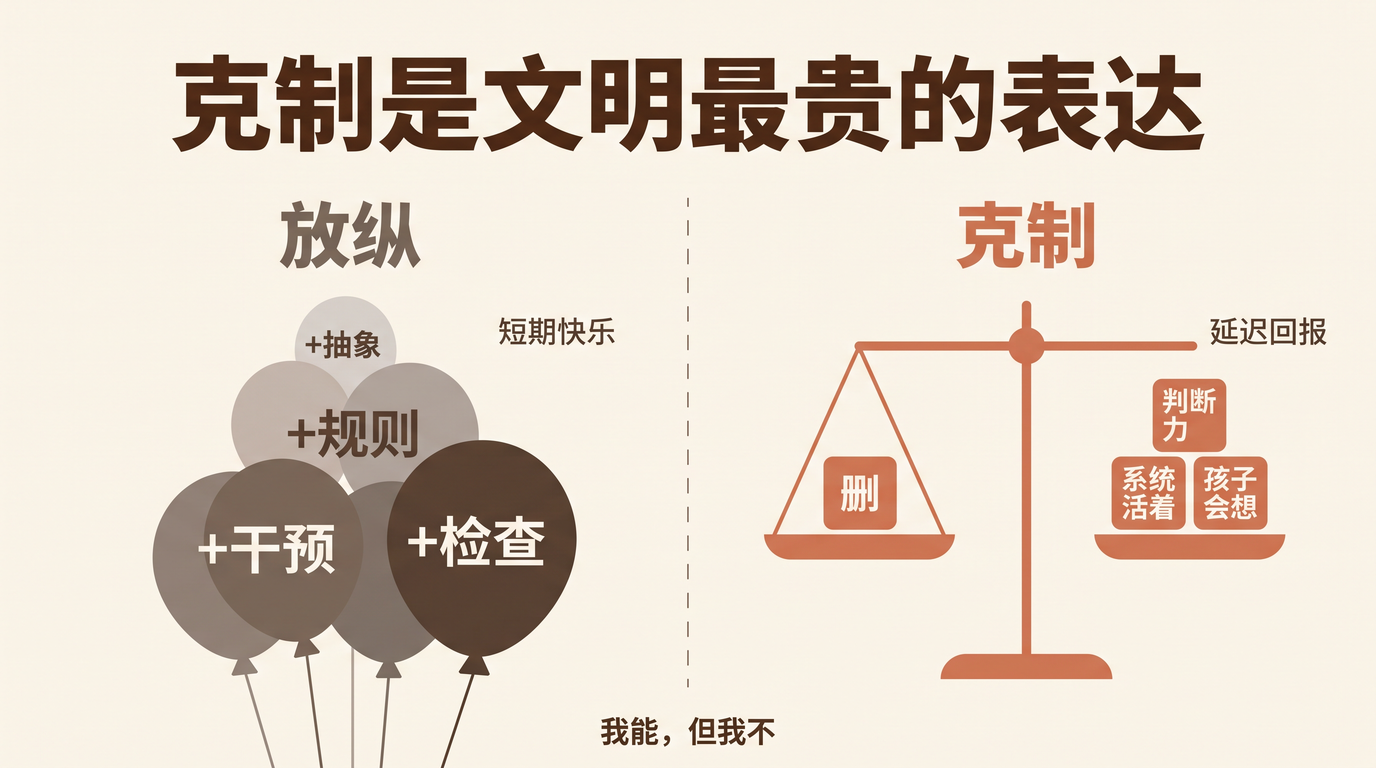
上个月,我们团队一位产品经理花了两周写了一份 40 页的 PRD,描述一个智能审批 Agent 的需求。用户故事、流程图、异常分支、验收标准,写得滴水不漏。
她把 PRD 丢给 Coding Agent,说:「按这个做。」
三天后 Agent 交付了。代码能跑,测试通过,接口对齐。但她试了五分钟就皱眉:「这不是我要的东西。」
哪里不对?她说不清。审批流程是对的,权限校验是对的,消息通知是对的。但 Agent 处理「领导已读不回超过 48 小时」的策略,不是她脑子里想的那个。PRD 里写的是「超时后自动提醒」,Agent 就老老实实给所有超时审批发了一轮提醒——包括那些「领导出差没看手机」的非紧急件。她真正想要的是「先判断这条审批是否紧急,紧急的才提醒,不紧急的等下次汇总」。
这个判断,她没写进 PRD。因为她觉得这是「常识」。
Agent 没有常识。Agent 只有你给它的判据。